13 KiB
课程作业
文献名称:Attention Is All You Need
Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in neural information processing systems, 2017, 30.
[TOC]
1. 文献解读
1.1. 引言
引言首先在第一段叙述了当时(2017年)的深度学习主流架构:RNN架构,以LSTM和GRU为代表的RNN在多项序列任务中取得了SOTA的结果,主要的研究趋势是不断提升递归语言模型和“encoder-decoder”架构的能力上限。
接着第二段叙述了RNN的不足,主要是其必须使用串行计算,必须依照序列的顺序性,并行计算困难。
而注意力机制的应用可以无视序列的先后顺序,捕捉序列间的关系。
因此文章提出一种新架构Transformer,完全使用注意力机制来捕捉输入输出序列之间的依赖关系,规避RNN的使用。实验证明,这种新架构在GPU上训练大幅加快,且达到了新的SOTA水平。
总结:
- 论文主题:提出一种新架构
- 解决问题:提出能够并行计算的架构替代RNN
- 技术思路:仅使用注意力机制处理输入输出序列
1.2. 算法
1.2.1 整体架构
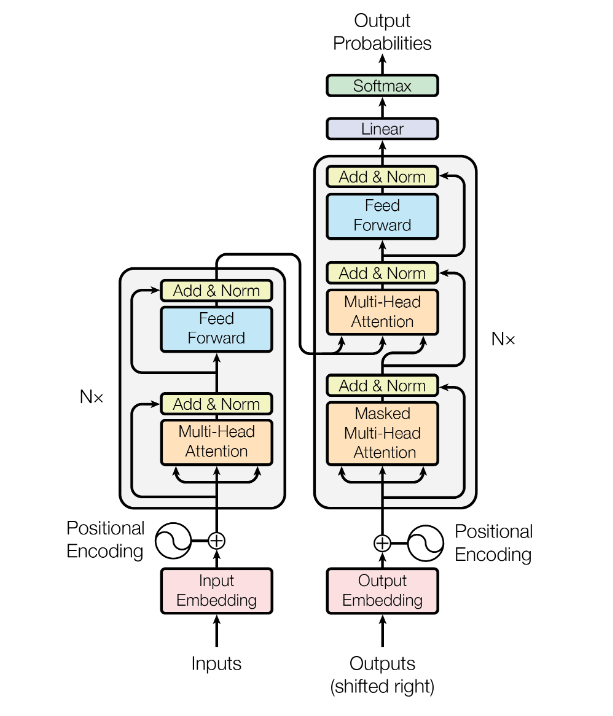
图1 子编码器架构
上图是Transformer架构的模型网络结构。
整个Transformer模型由$N=6$个这样的Encoder-Decoder对组成,如下图所示:
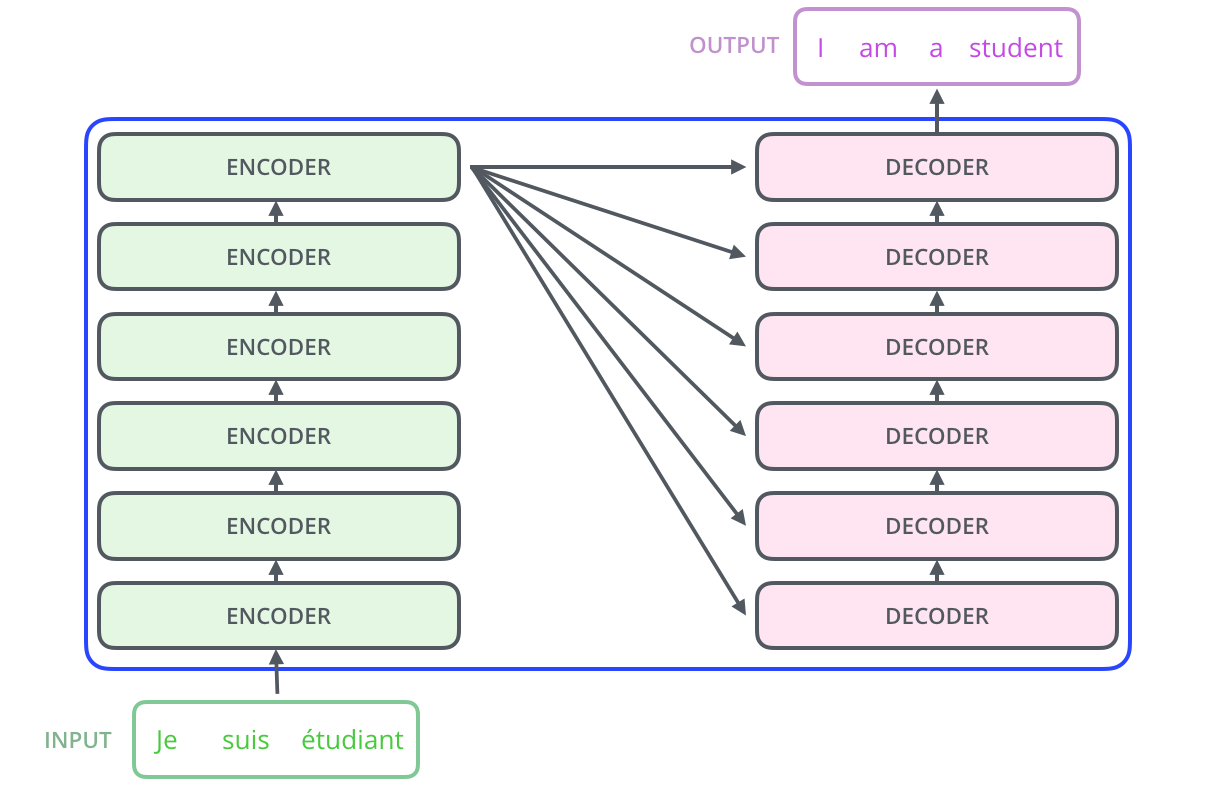
图2 编码-解码器架构
每个子编码器的架构相同,为图1所示,但是各个子编码器的模型权重不同;同理,每个子解码器的架构相同,权重不同。
因此,模型的数据处理过程如下:
- 对输入数据进行文本嵌入;
- 对输入数据进行位置编码;
- 将输入数据依次输入$N=6$层子编码器;
- 将最后一层子编码器的输出分别传入每层子解码器;
- 对目标数据进行文本嵌入;
- 对目标数据进行位置编码;
- 将目标数据依次输入$N=6$层子解码器;
- 使用全连接层和Softmax层将解码器的输出转换为预测值并输出。
1.2.2. 缩放点乘注意力
这一部分包含于多头注意力模块之中。
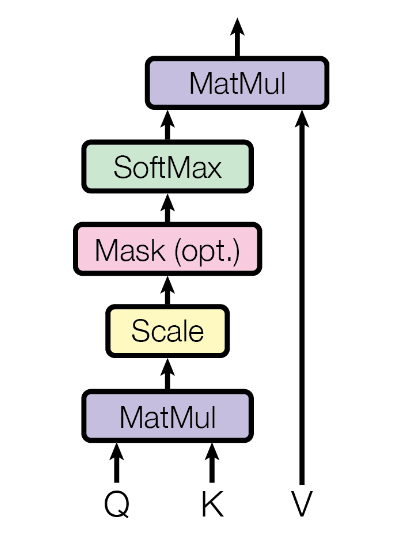
图3 缩放点乘注意力计算描述
计算公式如下:
\operatorname{Attention}(Q, K, V)=\operatorname{softmax}\left(\frac{Q K^{T}}{\sqrt{d_{k}}}\right) V
其中,输入的$Q$为查询(Query)向量,$K$为关键字(Key)向量,$V$为值(Value)向量,由输入token序列$X$计算得到:
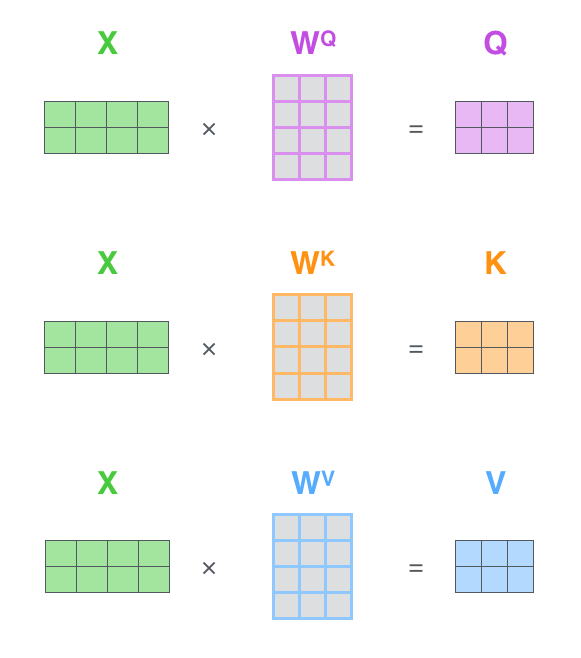
图4 自注意力矩阵计算描述
其中,$W^Q$、$W^K$和$W^V$都是待学习的权重。
接着,$QK^T$表示将查询向量$Q$与关键字向量$K$做内积,意在计算两者的相关性。查询与对应token的关键字的相关性越高,得到的结果矩阵中的对应值越高,受到注意力就会越高。将结果矩阵除以$\sqrt{d_{k}}$(避免较高值造成Softmax层的梯度消失),送进Softmax层进行概率计算。
得到概率矩阵后,将概率矩阵与值向量$V$相乘,作为对应token的值的权重。
最后,将加权的值向量输出。
注意力机制算法的核心思想是,对于每个token的键值对,查询与一个token的键越相似,就对该token的值越关注。
1.2.3. 多头注意力
这部分对应于图1中的Multi-Head Attention。
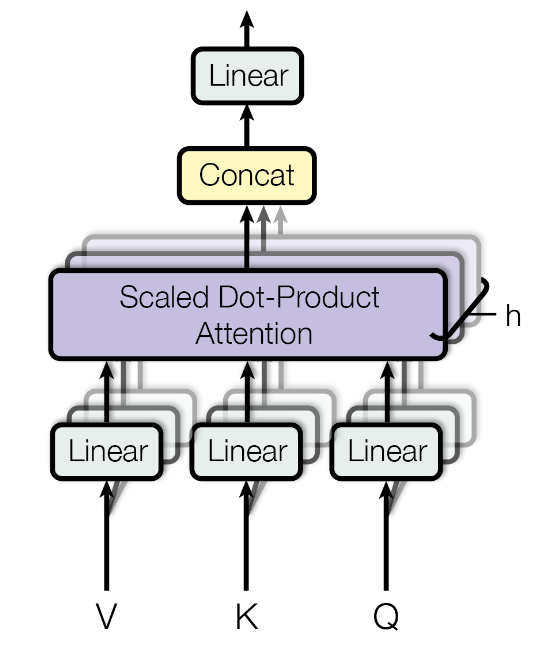
图5 多头注意力计算描述
计算公式如下:
\begin{align}
\begin{aligned}
\operatorname{MultiHead}(Q, K, V) & = \operatorname{Concat}\left(\operatorname{head}_{1}, \ldots, \operatorname{head}_{\mathrm{h}}\right) W^{O} \\
\text { where head } & = \operatorname{Attention}\left(Q W_{i}^{Q}, K W_{i}^{K}, V W_{i}^{V}\right)
\end{aligned}
\end{align}
多头注意力实际上是多个自注意力的叠加,类似卷积神经网络中多个通道特征,这样可以有效学习到多个不同的特征。
将查询向量$Q$、关键字向量$K$和值向量$V$复制$h=8$份($h$即为“多头”的头数),分别放入多个自注意力计算模块中计算特征。最后将得到的特征堆叠,送入全连接层融合。
1.2.4. 应用注意力机制
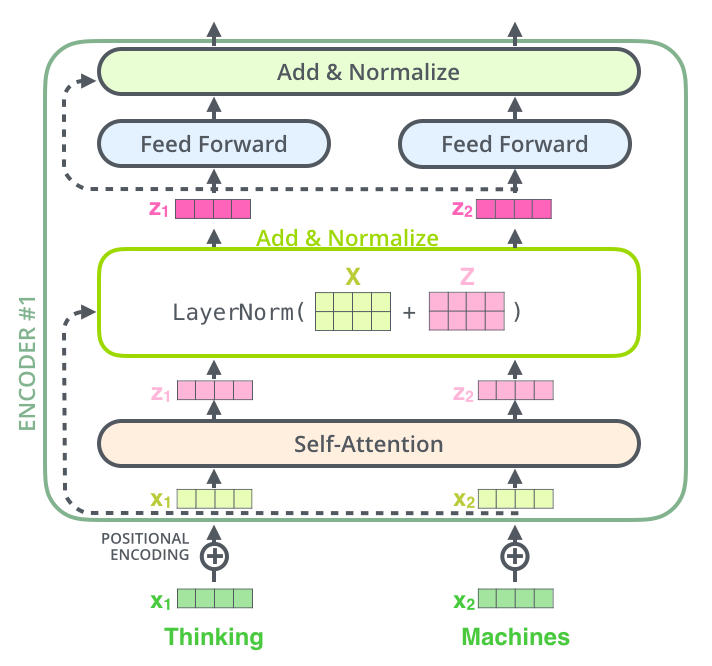
图6 子编码器计算流程
在编码器中,每一个子编码器都由以下计算流程依次组成:
- 输入token序列$X$进行多头注意力计算;
- 将$h$个自注意力模块计算结果使用全连接层整合;
- 与原输入序列$X$相加,构成残差网络,并进行层归一化;
- 将结果送入前馈网络;
- 进行残差计算,随后归一化,最后输出。
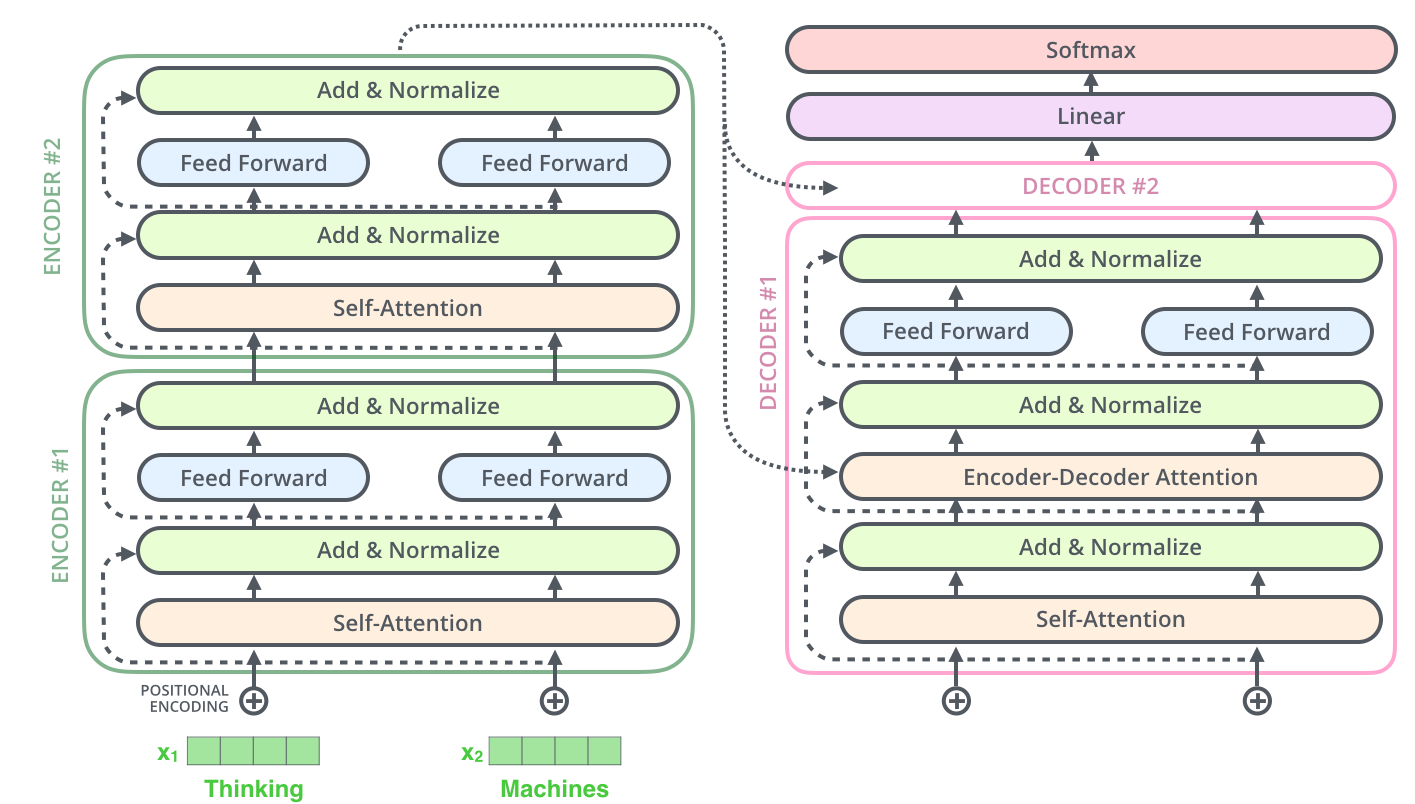
图7 编码解码器计算流程
在解码器中,每一个子解码器都由以下计算流程依次组成:
- 对目标token序列进行掩码处理;
- 送入多头注意力模块计算;
- 与输入的目标序列求和计算残差并归一化;
- 将编码器输出结果作为查询向量$Q$,从目标序列计算出关键字向量$K$和值向量$V$,输入自注意力模块计算;
- 与输入序列求和计算残差并归一化;
- 将结果送入前馈网络;
- 与输入序列求和计算残差并归一化,最后输出。
1.2.5. 前馈网络
计算公式如下:
FFN\left(x\right) = max\left(0, xW_1+b_1\right)W_2 + b_2
两层全连接层之间使用RELU作为激活层。
1.2.6. 掩码多头注意力
由于Transformer架构支持并行计算,当预测${Output}t$需要在时,不能向模型提供${Output}{t+1}$及之后的子序列,因此要对目标序列输入进行掩码。
比如一组数据为
{
Input: "i love computer speech technology",
Target: "我爱计算机语音技术"
}
希望预测Target[4]“机”时,只能向模型提供Target[0:4]“我爱计算”,而不能输入后面的序列,因此需要将其遮掩。
遮掩方法是让注意力公式的Softmax的输入为$-\infty$,那么得到的后面的token的注意力权重就几乎为0,达到遮住后面的token的效果。
即希望预测Target[4]“机”时,Softmax的输入相当于["我", "爱", "计", "算", "$-\infty$", "$-\infty$", "$-\infty$", "$-\infty$", "$-\infty$"],其中文字代表其对应的计算得到的注意力权重。
1.2.7. 位置编码
计算公式为:
\begin{aligned}
P E_{(\text {pos }, 2 i)} & =\sin \left(\operatorname{pos} / 10000^{2 i / d_{\text {model }}}\right) \\
P E_{(\text {pos }, 2 i+1)} & =\cos \left(\operatorname{pos} / 10000^{2 i / d_{\text {model }}}\right)
\end{aligned}
其中$pos$为token在序列中的下标,$2i$或$2i+1$为词向量的维度序号。即词向量维度为偶数时使用正弦函数,为奇数时使用余弦函数。
该函数满足以下性质:
-
对于一个词嵌入向量的不同元素,编码各不相同;
-
对于向量的同一个维度处,不同$pos$的编码不同。且$pos$间满足相对关系:
\left\{\begin{array}{l} P E(\text { pos }+k, 2 i)=P E(\text { pos }, 2 i) \times P E(k, 2 i+1)+P E(\text { pos, } 2 i+1) \times P E(k, 2 i) \\ P E(\text { pos }+k, 2 i+1)=P E(\text { pos }, 2 i+1) \times P E(k, 2 i+1)-P E(\text { pos }, 2 i) \times P E(k, 2 i) \end{array}\right.从实际意义上看,即例如Target[4]“机”的位置编码可以被Target[1]“爱”和Target[3]“算”的位置编码线性表示。
1.3. 结论
1.3.1. 实验结果
研究测试了“英语-德语”和“英语-法语”两项翻译任务。使用论文的默认模型配置,在8张P100上只需12小时就能把模型训练完。
研究使用了Adam优化器,并对学习率调度有一定的优化。模型有两种正则化方式:
- 每个子层后面有Dropout,丢弃概率0.1;
- 标签平滑。
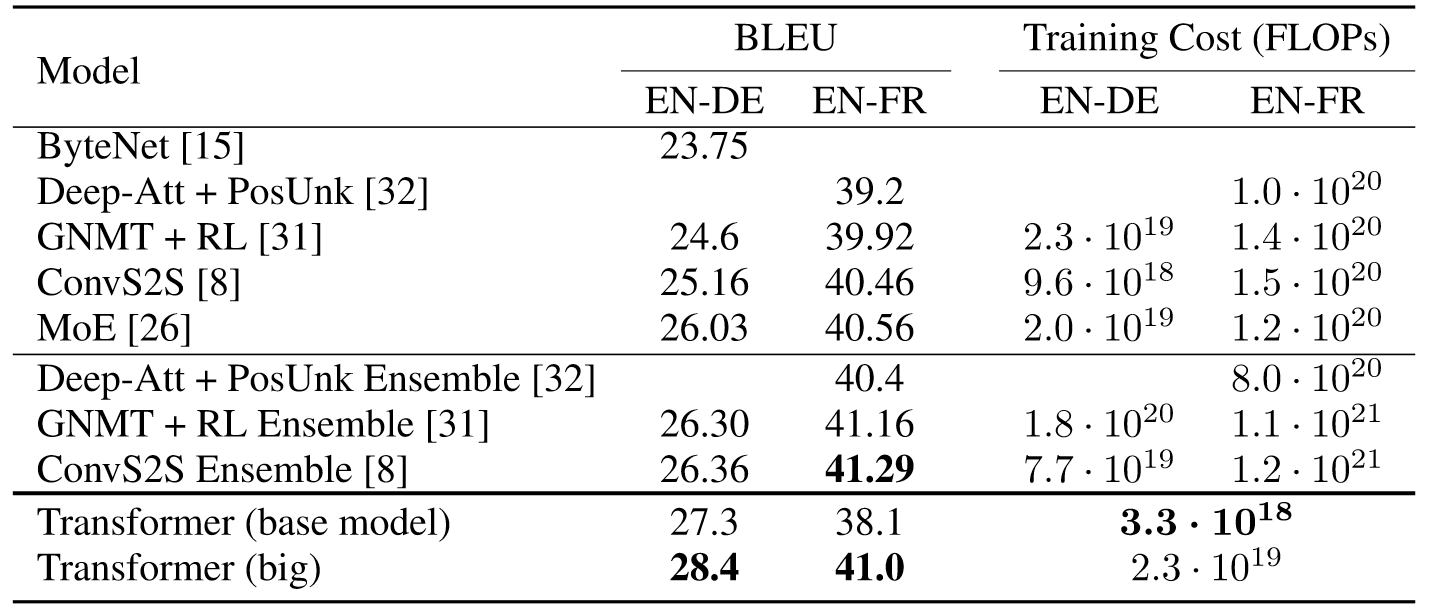
图8 翻译任务实验结果
实验表明,Transformer在翻译任务上胜过了所有其他模型,且训练时间大幅缩短。
论文同样展示了不同配置下Transformer的消融实验结果。
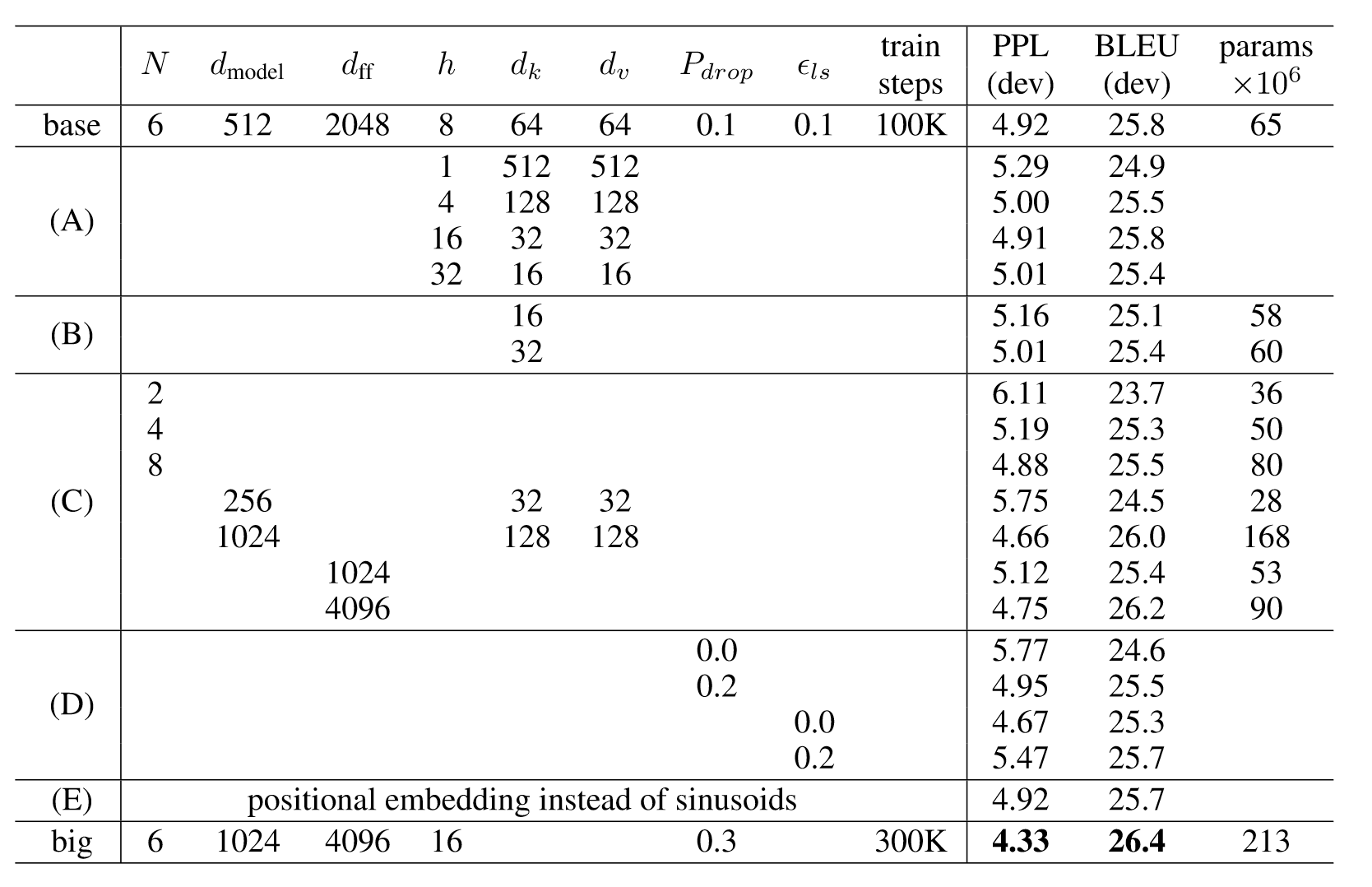
图9 消融实验结果
实验A表明,计算量不变的前提下,需要谨慎地调节$h$和$d_k$、$d_v$的比例,太大太小都不好。这些实验也说明,多头注意力比单头是要好的。实验B表明,$d_k$增加可以提升模型性能。作者认为,这说明计算key、value相关性是比较困难的,如果用更精巧的计算方式来代替点乘,可能可以提升性能。实验C, D表明,大模型是更优的,且dropout是必要的。如正文所写,实验E探究了可学习的位置编码。可学习的位置编码的效果和三角函数几乎一致。
1.3.2. 研究结论
Transformer这一仅由注意力机制构成的模型。Transformer的效果非常出色,不仅训练速度快了,还在两项翻译任务上胜过其他模型。
Transformer在未来还可能被应用到图像、音频或视频等的处理任务中。
1.4. 个人见解
在接触过的研究中,我使用过很多基于Transformer架构的模型。
在图片Caption任务中,我将Transformer与CNN和RNN结合的编码-解码器进行效果比较,后者的效果非常差,而Transformer可以达到较好的效果。
另外,基于Transformer架构的各类大模型可以达到很好的效果,其中我体验过商用的ChatGPT,也复现过开源的Llama2、LLaVA等VQA任务模型,使用过RoBERTa等BERT-base模型完成token分类任务,使用ViT为CLIP等图像分类任务模型进行图像特征提取等。
由于学识不足,个人无法独立给出对Transformer架构本身的评价。因此,本人查阅了近年来对Transformer进行改进或替代的研究,搜集到如下几点问题或改进方法:
- Transformer模型中自注意力机制的计算量会随着上下文长度的增加呈平方级增长,计算效率非常低。最近一项研究Mamba: Linear-Time Sequence Modeling with Selective State Spaces针对长文本有更好的效果;
- SIMPLIFYING TRANSFORMER BLOCKS发现可以移除一些Transformer模块的部分,比如残差连接、归一化层和值参数以及MLP序列化子块(有利于并行布局),以简化类似 GPT 的解码器架构以及编码器式BERT模型。